 こんにちは。昨年10月にロコガイドへ入社した丹羽です。現在は技術部インフラ基盤グループに所属し、トクバイを始めロコガイドのサービスをインフラ面からサポートできるよう日々実践と勉強を続けています。先日、AWSのソリューションアーキテクト試験に再合格できてホッとしました。
こんにちは。昨年10月にロコガイドへ入社した丹羽です。現在は技術部インフラ基盤グループに所属し、トクバイを始めロコガイドのサービスをインフラ面からサポートできるよう日々実践と勉強を続けています。先日、AWSのソリューションアーキテクト試験に再合格できてホッとしました。
この記事では、AWSのマネージドサービスの1つであるAmazon Timestreamを取り上げ、概要やサービスに触ってみた感想などを紹介します。一般公開されたのが2020年10月なので新鮮味はありませんが、昨年夏ごろから東京リージョンでも利用できるようになったことで、今後実際に導入を検討する事例も出てくるでしょう。
時系列データベースとは
Amazon Timestreamは時系列データベースですが、まずは時系列DBが何かについておさらいしておきましょう。
その名の通りタイムスタンプと値をセットにして格納するデータベースで、リレーショナルDBに比べて時系列での検索・分析や挿入時のスループット、コストパフォーマンスに優れています。その反面、データの更新や削除は苦手とされています。
主な用途としてよく挙げられるのは、センサーなどIoT機器のデータ収集、サーバのログやメトリクス蓄積、株価など金融関連のデータ解析や商品の需要予測など。
OSSの実装ではInfluxDBが有名です。今回の記事執筆にあたりDB-Engines Rankingをのぞいてみたところ、KdbやGraphiteなど恥ずかしながら名前も知らなかったDBが色々ありました。Prometheusも監視システムとして有名ですが、DB部分は時系列DBです。
Amazon Timestreamとは
ここからは改めてAmazon Timestreamについて説明します。
Amazon Timestreamはフルマネージド・サーバーレスの時系列データベースです。コンピューティングリソースとストレージを自動で拡張し、使用分に応じて従量課金されます。
AWSコンソールにクエリエディターが搭載されているので、データを取り込めばすぐクエリを実行できます。SQLを部分的にサポートしており、リレーショナルDBと同じ要領でSELECTが実行できるのも嬉しいところです。ただ前項でも触れた通り、UPDATEやDELETE文はサポートしていません。
DELETEがないならどうやって過去のデータを削除するかというと、データのライフサイクル設定というものがあります。Timestreamのストレージは階層化されており、取り込まれたデータはまず高速なメモリ階層に置かれます。一定期間が経過するとやや低速な磁気ディスク階層に移動し、さらに一定期間が経過すると削除されます。
勝手に削除されたら困るじゃないかと思われるでしょうが、ライフサイクル期間は自由に設定可能で、磁気ディスク階層は最長200年も保持可能だそうなので実用レベルでは半永久的に保存できると考えていいでしょう。また、クエリを実行する上でデータがメモリにあるかディスクにあるかは意識する必要がなく、Timestream側で両方のデータを統一的に検索してくれます。
定期的にクエリを実行して、実行結果を保存するスケジュール機能もサポートされています。こちらはRedshiftなどにもある機能ですが、時系列DBだけにリアルタイムで定点観測ができるのは売りと言えるでしょう。
AWSの他サービスとの比較
AWSには既にたくさんのサービスが存在しますが、その中でTimestreamはどのような位置付けになるでしょうか。
まず、ストリーミングデータ(多数のソースから継続的に送られてくるデータ)処理という観点では、Amazon Kinesis Data StreamsとAmazon Managed Streaming for Apache Kafka(Amazon MSK)が既にあります。Kinesis Data Streamsはソースからのデータを受信するWebエンドポイントを提供し、またMSKはメッセージブローカーとしてストリーミングデータを中継します。この両者はKinesis Data Analytics Studioという別サービスと組み合わせることで、保持しているデータの分析も可能です。
こう書くとTimestreamと競合しそうにも思えますが、Kinesis Data StreamsとMSKはストリーミングデータの通過点であって保管場所ではありません。そのため、最終的なデータの保管場所としてTimestreamを採用することが考えられます。
またサーバーレスDBという観点では、Aurora Serverless、Redshift Serverless、DynamoDBが思いつきます。先述した通り、Timestreamには更新や削除がなく、アプリケーションのデータストアとして使うのは難しいので、Aurora ServerlessやDynamoDBとの比較はあまり意味がないでしょう。
一方、Redshift ServerlessはリレーショナルDBではありますが、データ分析に重点を置いているなどTimestreamと立ち位置が似ています。この両者の使い分けですが、まずRedshiftはPostgreSQLと互換性があるため既存の接続ライブラリなどが使いまわせるのに対し、TimestreamはAPIを経由する必要があります。さらに両者はともに従量課金ではありますが、Redshift Serverlessがワークロード時間に応じて課金されるのに対し、Timestreamの書き込み・読み取りはデータ量に応じて課金されます。このことから、1日のうち特定の時間帯だけ使用するようなケースではRedshift Serverless、逆に継続的に書き込みが発生したり1回のクエリに長時間かかったりするケースではTimestreamといった使い分けが見えてくるでしょう。
実際に触ってみる
説明が長々と続いてしまったので、ここからは実際に操作をしてみます。
Timestreamのコンソールから、データベースを作成してみます。この際、すぐに操作テストができるようデータの含まれたサンプルデータベースを選択します。
データベースが作成され、その中にIoTMultiというサンプルデータのテーブルが作成されています。

どのようなデータが格納されているか見てみましょう。
クエリエディタを開くとIoTMultiテーブルが表示されているので、データのプレビューでSQLクエリを生成し、実行してみます。
一見リレーショナルDBと変わりない表形式で結果が返ってきました。項目を見た感じ、自動車のIoTセンサーから送られるデータという想定でしょうか。

続いてスキーマを表示を見てみます。列名とデータ型の他に、Timestream attribute type(属性タイプ)という項目があり、DIMENSIONやMULTI、MEASURE_NAMEなどの値が入っています。これについては少し解説が必要でしょう。

まず、TIMESTREAMレコードの属性にはTIMESTAMP, DIMENSION, MEASURE, MEASURE_NAMEがあります。属性タイプにもこれに対応したTIMESTAMP, DIMENSION, MEASURE_NAMEという値がありますが、MEASUREだけは存在せず、MEASURE_VALUEまたはMULTIのどちらかの値を取ります。この理由については後述します。
TIMESTAMPはその名の通りレコードが記録された日時を示しており、時系列データベースである以上必須です。
DIMENSIONはレコードのメタデータ、MEASUREはレコードのメトリクスとされています。サンプルデータで言うと車の属性を表すmodel(車種)やfuel_capacity(燃料の最大容量)がDIMENSION、実際にセンサーが測定したfuel-reading(燃料メーター値)やspeed(速度)がMEASUREです。MEASUREの値をDIMENSIONで集約するような使い方を想定していると思われます。
MEASURE_NAMEはその名の通りMEASUREの名前です。それは列名では…? と思ってしまいますが、実はTimestreamは2021年11月のアップデートまでMEASUREを1レコードに1個しか持てませんでした。1個のみの場合、属性タイプはMEASURE_VALUEに、複数個を持つ場合はMULTIになります。1個のみしか持てなかった時代は、同じタイムスタンプの複数データを記録するにはいわゆるデータの縦持ちをしなければならず、MEASURE_NAMEもその名残と思われます。最初から複数個を使える現在では、そこまで意識しなくてもよいでしょう。
AWSコンソールだけでなく、APIからの操作も試してみます。AWSからTimestreamのサンプルアプリケーションが提供されているので、こちらのPython実装を使用します。CSVインポートを試してみましょう。

6万行ほどあるCSVがインポートされていき、インポート後にクエリが実行され、クエリ結果が返ってくるのがわかります。
続いてスケジュールクエリを作成してみましょう。

スケジュールクエリとそれに関連するAWSリソースが作成され、スケジュールクエリが一度だけ実行されます。スケジュールクエリは関連する要素が多いので、このサンプルで作成されるリソースを参考にするのも良いでしょう。
もう少し時系列DBらしい使い方をするため、時系列の操作に特化した関数を試してみましょう。
まずはBIN関数です。これは指定した間隔でタイムスタンプを整えてくれます。


30秒単位でまとまっていますね。
続いて、CREATE_TIME_SERIES関数です。これはデータを通常の表形式データ(フラットモデル)から時系列モデルのデータに変換してくれます。


時系列モデルのデータはこのようにタイムスタンプとメジャーの配列として表現されます。
時系列モデルのデータにはINTERPOLATE関数が使えます。これは時系列データの間の数値を近似値で補間するというものです。ここでは線形補間の関数INTERPOLATE_LINEARを使ってみます。


時系列データの間隔が先ほどの30秒から15秒になっているのがわかりますでしょうか? この15秒間隔のデータが自動で補間されたものです。今回例に使っているCPU使用率ではあまり意味がありませんが、より分析的なタスクでは活用できる場面もあるでしょう。
最後に、時系列モデルのデータを扱いやすいように再度フラットモデルに戻します。時系列モデルの列をCROSS JOIN UNNESTで展開するだけです。


さて、最近ではデータといえば可視化がセットです。TimestreamはAmazon QuicksightやGrafanaなどに対応していますが、ここではGrafanaで手軽に可視化を試してみます。
TimestreamプラグインをインストールしたGrafanaコンテナを起動してログインし、データソースでTimestreamを選択します。GrafanaからTimestreamに接続するための情報を設定しますが、このうちエンドポイントの情報はコンソールでは公開されていないので、aws-cliなどを通じて取得する必要があります。
Timestreamに接続できたところで、適当なクエリを流してグラフを表示してみます。まずは生のデータポイントの表示。

点が多すぎて、グラフとしては見づらいものになってしまいました。ここでBIN関数を使って1分単位で集約してみます。

点が整理されて、増減の傾向が分かりやすくなりました。先に紹介した時系列補間のクエリも試してみます。
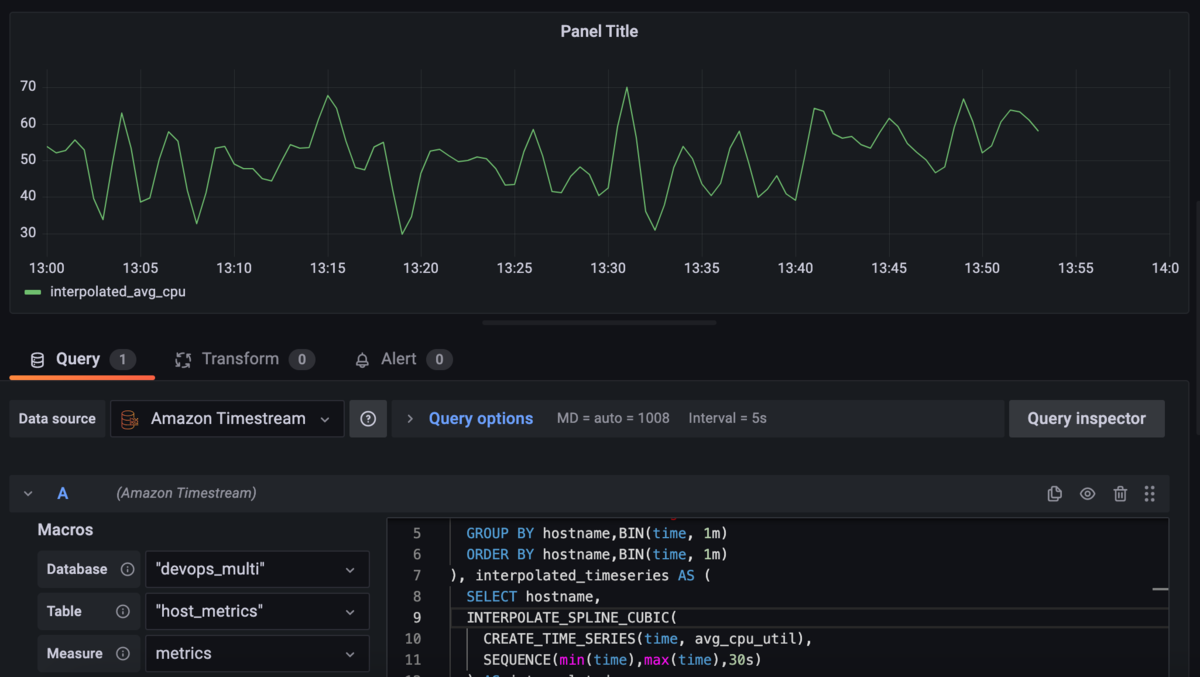
3次スプライン補間を試したところ、滑らかなグラフになりました。
想定されるユースケース
ここまでTimestreamの特徴や機能を見てきて、では実際にどう使うかということを考えてみます。
真っ先に思いつくのはやはりログの集約および分析です。一箇所に集約しつつ、気軽にクエリを実行できて、ライフサイクルも柔軟に設定できるということが1つのサービスで実現できるというのは魅力的です。fluentdのプラグインが既に存在するのも地味に嬉しい。コスト面ではS3+Athenaに劣りますし、完璧なサービスというわけではありませんが、既存のデータ環境の見直しなどで候補に加えるのはありでしょう。
その際、少し残念なのがDatabase Migration Serviceに未対応であること。DMSでKinesis Datastreamにデータを投入し、そこからApache Flink Connectorを使ってTimestreamに保存するという構成は取れそうですが、いかにも煩雑です。いずれDMSがTimestreamにも対応することを期待したいです。
もう1つのユースケースはユーザー動向の分析です。時系列関数を活用することでユーザーの行動ログから新しい知見が得られますし、RDSほどには費用を意識せずにデータを保存できるので、リアルタイムの分析も長期間の分析もこれ1つで対応可能です。分析業務にはまだ深くコミットしていないので、この辺りは推測込みになりますが…。
まとめ
実際に業務上で使用するかどうかにかかわらず、サービスやソフトウェアに触れることは勉強になります。今回のTimestreamも普通のRDBで十分なのでは? と半ば思いながらも、こういうニッチなサービスが存在する理由を考えながら触っていました。こうした経験を積み重ねて、しかるべき時に最適な技術を選定する鑑定眼を養えればと思います。