
はじめに
インフラ基盤グループの大谷です。最近、チームの頑張りでMySQL5.6のRDSインスタンスをアップデートしきることができました。しばらくEOLに気を揉まずに済みそうで大変晴れやかな気分です。
そして嬉しい出来事とはまったく別に、MySQLのレプリケーションエラーを起因としたサービス障害が発生しました。対応の過程でいくつかの知見を得られたため、紹介したいと思います。
当該システムの構成について
システム構成
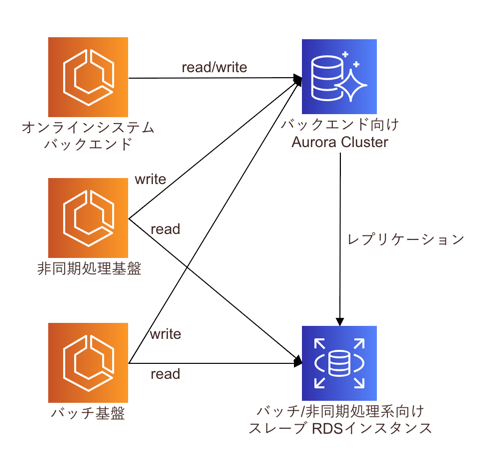
障害が発生した非同期処理・バッチ基盤のDB構成について説明します。構成としてはシンプルで、オンラインサービス(バックエンド)のDB負荷と非同期/バッチ処理のDB負荷を分散させるため、非同期/バッチ処理をAuroraからレプリケーションしたRDSインスタンスに振り分けていました。
この構成を採用したのは2018年初頭ですが、当時はワークロードによってAuroraクラスターのリードレプリカへリクエストを振り分けるAWS機能がなかったため、自前でMySQL機能を用いてレプリケーション設定を行いました。
ちなみに、当時はこのようなAWSドキュメントはなかったと記憶しているのですが、今は RDS Aurora -> RDS MySQL間のレプリケーションについてのドキュメントが公式に整備されているようです。(参考リンク: Aurora と MySQL との間、または Aurora と別の Aurora DB クラスターとの間のレプリケーション (バイナリログレプリケーション))
また、ユーザー個人情報などの、セキュリティレベルを高く扱わなければいけない情報(個人情報等の機微情報)を含むテーブルは、テーブル名に任意のprefixを付与して運用しています。 本記事ではこのprefixを付与したテーブルを便宜上 secret_table として説明します。
サービスの運用上、社内の開発者向けに secret_table 以外のテーブルの参照権限を付与する必要がありますが、これはストアドプロシージャによるGrant文の定期実行にて対応していました。このGrant文が後のトラブルの引き金となります。
何が起きたか
影響
簡潔に説明しますと、タイトルの通りレプリケーションエラーが発生しました。
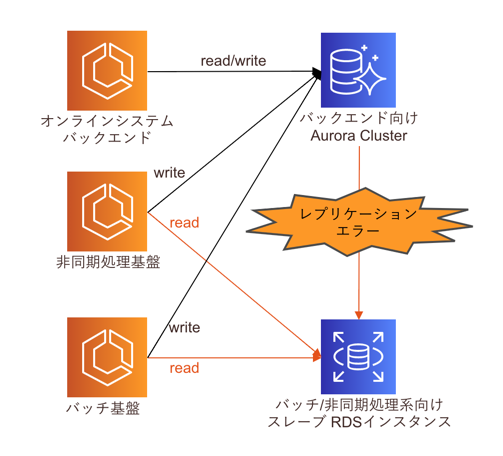
具体的には、前述のストアドプロシージャで数分間隔で定期実行しているGrant文がレプリケーション先のスレーブRDSインスタンス上でエラーとなり、エラー発生以降のレプリケーション処理がすべて停止しました。このため各種データが最新化されない状況で、非同期処理/バッチ処理が走りデータに不整合が発生しました。
原因
原因は大きく2つあります。
ひとつ目は、レプリケーション遅延の監視漏れです。通常、AWS機能を用いてRDSリードレプリカインスタンスを作成した場合、自動でCloudWatchへレプリケーション遅延メトリクスを収集してくれます。
弊社でも全ての CloudWatch 上のレプリケーション遅延監視メトリクスに監視アラートを設定していましたが、今回のように自前でMySQL機能を用いてレプリケーション設定をした場合、SHOW SLAVE STATUS コマンドのSeconds_Behind_Master を収集してカスタムメトリクスを作成する必要があります。
監視漏れが直接事象のトリガを引いたわけではないですが、レプリケーションエラーの検知後に即時、何らかのリカバリ対処をしていればデータ不整合の影響を最小限に抑えられたはずです。しかし、実際に事象を認識したのはエラー発生から時間が経過した後でした。
ふたつ目は、前述のストアドプロシージャと、「特定のテーブルをスワップさせるバッチ処理」の存在です。
Grant文を定期実行しているストアドプロシージャは以下のような処理を行っていました
- ①. Grant文の対象テーブル一覧を生成するため、MySQLのINFORMATION_SCHEMA.TABLESから
secret_tableを除くテーブル一覧をSELECT - ②. ①に対してGrant文を順次実行し、開発向けMySQLユーザーへ権限を付与
一方、本番テーブルをスワップさせるバッチはとある集計処理を行うバッチで以下のような処理を行っていました
- A: 集計処理用にテンポラリテーブルを作成
- B: テンポラリテーブルに処理データを書き込み
- C: テンポラリテーブルと本番テーブルをそれぞれリネームしてテーブルを入れ替え
- D: 旧本番テーブルを削除
レプリケーションマスターのバイナリログを調査したところ、この2つの処理が最悪のタイミングで重なりあい以下のような順番で処理が走ったことがわかりました。
- A: 集計処理用にテンポラリテーブルを作成
- B: テンポラリテーブルに処理データを書き込み
- C: テンポラリテーブルと本番テーブルをそれぞれリネームしてテーブルを入れ替え
- ①. INFORMATION_SCHEMA.TABLESから
secret_tableを除くテーブル一覧をSELECT - D: 旧本番テーブルを削除
- ②. ①に対してGrant文を順次実行し、開発向けMySQLユーザーへ権限を付与
通常、バッチ処理のCとDの間はコンマ数秒の差ですが、この時たまたま①のGrant文の対象を抽出するSELECT文が走ったときに削除予定のテーブルを対象としてしまい、②のGrant文の実行時に削除済みテーブルへのGrant文の実行でエラーが発生し、レプリケーションが停止してしまいました
是正対処
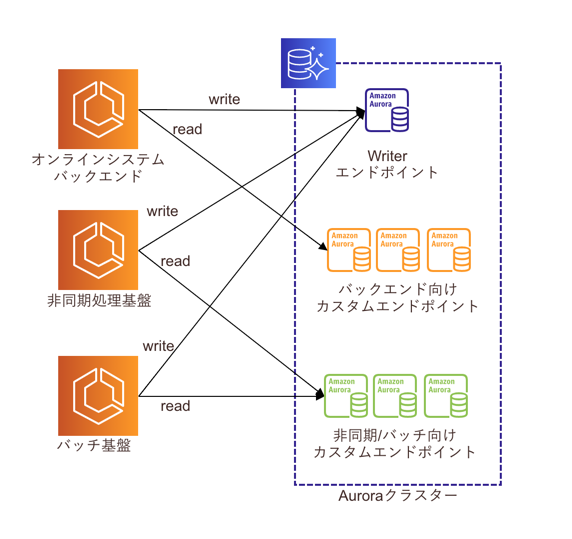
是正対処としてMySQLレプリケーションを利用した構成からAuroraカスタムエンドポイントへの移行を行いました。
Auroraカスタムエンドポイントとは、Auroraリードレプリカの組み合わせを自由に選択してエンドポイントを作成できるサービスです。元々レプリケーションを導入した目的がオンラインバックエンドと非同期/バッチ処理のワークロード負荷の分割だったのでまさにこのような状況下でうってつけの機能でした。
導入にあたりいくつか課題がありましたが、特に考慮が必要だったのがAuroraリードレプリカのAutoscalingです。一つのAuroraクラスタ内に、バックエンドと非同期処理/バッチの2つのワークロードが混在することになるため、AWSデフォルトの事前定義メトリクス(RDSReaderAverageCPUUtilizationやRDSReaderAverageDatabaseConnections)を利用してAutoscalingを組むと、意図したタイミングでAutoscalingが発動しません。
最終的に以下のような構成を取ることとなりました。
- 負荷傾向の分散のため、カスタムエンドポイントを利用してオンラインバックエンドと非同期/バッチ処理向けでエンドポイントを分割させる
- AuroraリードレプリカのAutoscalingはカスタムメトリクスを作成し、バックエンド側の1インスタンスのCPU使用率を指定する(参考リンク:Aurora レプリカでの Amazon Aurora Auto Scaling の使用 )
- トリガとしたインスタンスへフェイルオーバーしないようフェイルオーバー優先度を調整しておく
- AutoscalingポリシーはTerraformで管理
得られた知見
今回の事象で得られた知見についていくつかご紹介します。
1. 各種RDSのログはすぐに調べられるようにしておくと便利
マネジメントコンソール上に表示されるログ情報やインスタンスに乗り込んで得られる情報だけでは調査に限界があります。事前にawscliやmysqlbinlogを利用してRDSの必要な各種ログを手元にダウンロードできるよう、ワンライナーやスクリプトを用意しておくと便利です。
# 参考リンク
2. 監視漏れはおきるので棚卸しをしよう
原因のひとつは言ってみれば単純な監視漏れですが、事象が発生するまで関係者全員が当該箇所の監視は実施されているものと思い込んでいました。日ごろ別のインスタンスからレプリケーション遅延のエラーメッセージを受け取っていたこと等も思い込みが発生した一つの要因です。しかし、監視していたつもりが監視できていなかったケースはままある話でもあります。ロコガイドでは今回の一件を受けて、特にサービス上絶対に止まって欲しくないシステム系統について改めて監視の棚卸しを行い、各種設定内容の見直しを実施しました。
3. 積極的にマネージドサービスを利用していこう
当初のレプリケーション構成を構築後、RDSの機能としてカスタムエンドポイントなるものがリリースされていることは認識していました。ただ、現状すでに動いている構成を積極的に変更する理由がなかったため、いつか移行すればいい程度の認識でずるずると時間が経ってしまい、今回のような事象が発生してしまいました。本来であれば、もっと早くAWS機能で代替可能か否か、コストや機能、性能を検証した上で移行の可否を判断をすべきでした。
4. ポストモーテムの共有はGoogleDocsが便利
今回の対応中にGoogleDocsを利用して情報共有を行いました。復旧対応、影響調査、原因調査、是正措置の担当者を割り振り後、各人の調査・作業状況がリアルタイムに反映されていくため非常に便利です。SRE サイトリライアビリティエンジニアリング(15章)でも言及がありますが、Googleもポストモーテムの共有にGoogleDocsを利用されているようです。
最後に
今回は最近ロコガイドで発生したサービス障害の事例についてご紹介しました。実は個人的に自社・他社を問わずポストモーテムや障害報告書の類を読むのが好きな質なのですが、みなさま楽しんでいただけたでしょうか。 ロコガイドではよりサービスの信頼性を引き上げるべくSREを募集しています。興味のある方はぜひカジュアルにお話しましょう。